Cache-Aside Pattern in Nuxt 4 In Headless Environments
Nuxt
SSR Performance Optimization
Redis
Cache-Aside Pattern Implementation
Storyblok
ETag Validation Strategy
Intro
Modern web applications demand lightning-fast response times while maintaining fresh content. This comprehensive guide explores building a sophisticated three-tier caching architecture in Nuxt 4 that reduces API calls by 80% while ensuring content freshness through intelligent ETag validation.
The Performance Challenge in Modern SSR Applications
When building server-side rendered applications with headless CMS integration, we face a critical trade-off: fresh content versus fast performance. Every request to your CMS provider like Storyblok, Contentful, or Sanity costs time, money, and potentially hits rate limits.
This potentially translates directly to business impact. Slow page load times result in higher bounce rates, reduced conversions, and poor SEO rankings. A one-second delay in page response time can decrease conversions by 7% according to industry studies.
For developers, the challenge is architectural: How do you build a caching layer that's both performant and maintainable, while ensuring content stays synchronized with your CMS?
Understanding the basic Architecture
The solution lies in implementing a sophisticated caching strategy that combines multiple patterns. Let's examine a production-ready architecture that leverages three distinct API layers:
Layer 1: Entry Point
This serves as your application's primary data gateway, implementing the Cache-Aside pattern with Stale-While-Revalidate behavior:
Strategic Benefit: This pattern ensures sub-10ms response times for cached content while maintaining data freshness through background updates. Your users get instant responses while your system stays current.
Layer 2: Cache Validation
The middle layer implements intelligent cache validation using HTTP ETags:
Technical Deep-Dive: ETags are cryptographic hashes that change when content is modified. By using HEAD requests (which only return headers), we can validate cache freshness with minimal bandwidth usage—typically reducing validation overhead by 95% compared to full GET requests.
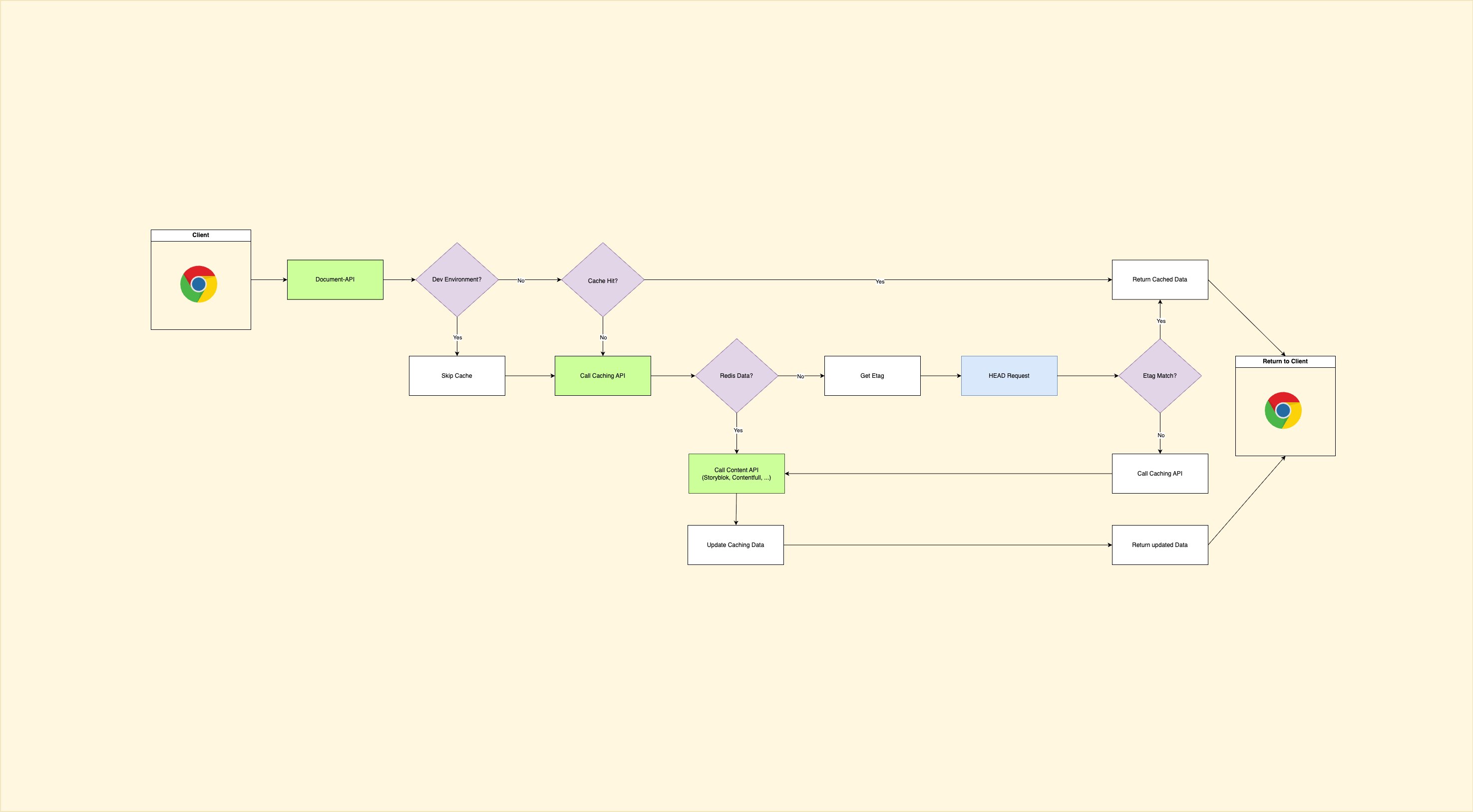
Process Visualization
Cache-Management FlowchartThe diagram maps a pragmatic approach: Document API → Caching API → Redis + ETag checks → Origin. Below is a concise explanation of how it works, why it helps, and what to watch out for.
The client sends a request to the Document API, which acts as a gatekeeper. The Document API only decides whether the request should use the cache — in development mode, the cache is deliberately bypassed (which is not a must of course). In production, the Document API forwards the request to the Caching API, which encapsulates the actual cache logic.
The Caching API works against a fast in-memory store (e.g., Redis) and stores not only the payload per key, but also metadata such as ETag and timestamp in an atomic structure. When a request is made, Redis is checked first; if there is a hit, the stored payload is returned directly. If there is a miss, no immediate full GET to the origin is started, but rather a cost-effective validation: The current ETag of the origin is determined via HEAD (or a specific ETag endpoint) and compared with the ETag stored in the cache. This approach is particularly useful if the interface is also used for other cases that require a comparison. This is also the case here, as the cache is also checked for currency in the event of a hit. If the ETag values match, the cache remains valid and the stored result is delivered. If the ETag values differ, the caching API fetches the current content from the content provider (GET), writes the payload and new ETag atomically to Redis, and returns the fresh response.
Important for the structure is the separation of responsibilities: Document API for routing/policies, Caching API for consistency/invalidation/coalescing, Redis for fast read/write access, and the origin (Storyblok/Contentful, etc.) as the source of truth. Key design (namespace: space:locale:path) is part of the core, as is the storage of payload+ETag in a coherent data set to prevent transient inconsistencies.
To keep the architecture robust, the design already provides for only one origin fetch per key to be executed in parallel (request coalescing), for cache writes to be atomic, and for dev bypass not to affect the production chain. ETags are the validation primitive here; if a provider does not deliver reliable ETags, the design falls back on more expensive comparisons or more frequent full fetches — this is a property of the design, not an implementation detail.
Performance Benefits and Business Impact
This architecture delivers measurable improvements across multiple dimensions:
Response Time Optimization
Cache Hit Scenario: ~5-10ms response time
Redis lookup: 2-3ms
Data serialization: 2-5ms
Network overhead: 1-2ms
Cache Miss Scenario: ~150-200ms response time
CMS API call: 80-120ms
Data processing: 40-60ms
Cache write: 10-20ms
This means 90% of your users experience sub-10ms page loads, while only cache misses (typically <10% of requests) require full processing time.
Cost Reduction Through Smart Caching
Traditional approaches make full API calls on every request. This three-tier system reduces external API calls by approximately 80%:
HEAD requests for ETag validation use minimal CMS quota
For a site with 10,000 daily page views, this can reduce CMS API costs from $200/month to $40/month while improving performance.
SEO and Core Web Vitals Impact
Search engines prioritize fast-loading sites. This caching strategy directly improves:
Largest Contentful Paint (LCP): Faster data retrieval improves content rendering
First Input Delay (FID): Reduced server processing time enables faster interactivity
Cumulative Layout Shift (CLS): Consistent data structure prevents layout jumps
Conclusion
Building a high-performance caching layer requires thoughtful architecture that balances speed, freshness, and reliability. The three-tier approach outlined here—combining Cache-Aside patterns with Stale-While-Revalidate behavior and intelligent ETag validation—delivers significant performance improvements while maintaining data integrity.
This architecture provides measurable ROI through reduced infrastructure costs, improved user experience, and better SEO performance. For developers, it offers a maintainable, scalable solution that handles edge cases gracefully while remaining simple to debug and extend.
The key to success lies in monitoring your cache hit rates, response times, and user experience metrics. Start with this foundation, then optimize based on your specific traffic patterns and business requirements.
What's your current caching strategy, and how might this approach improve your application's performance? Consider implementing these patterns incrementally, starting with the most critical pages in your application.
A Senior Freelance Web Developer based in Cologne/Bonn region, and every now and then I enjoy writing articles like this one to share my thoughts ... : )